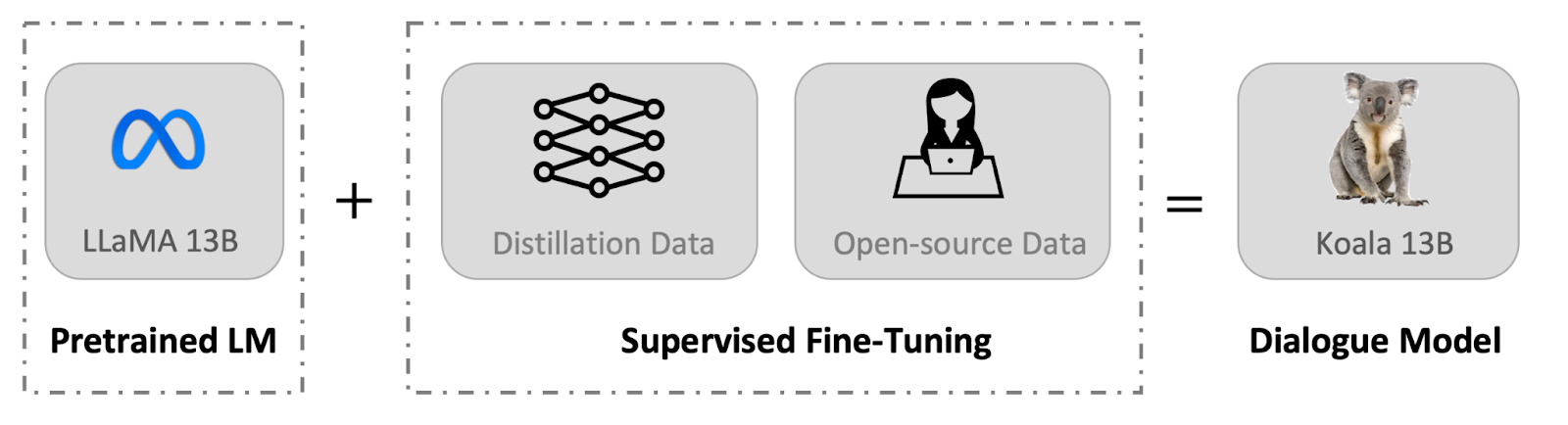
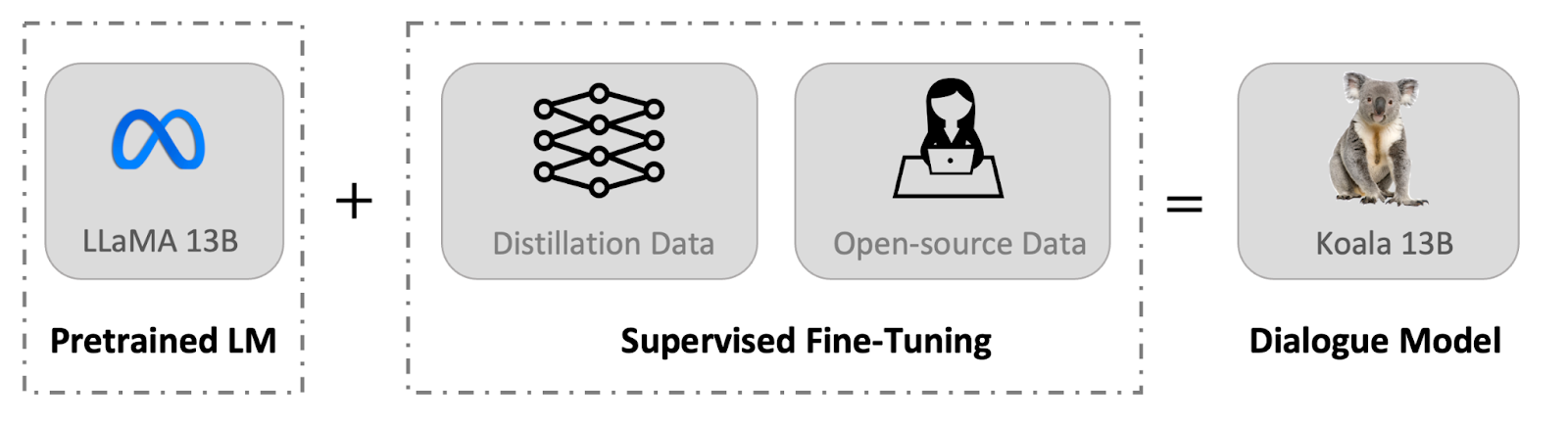
On this put up, we introduce Koala, a chatbot skilled by fine-tuning Meta’s LLaMA on dialogue knowledge gathered from the online. We describe the dataset curation and coaching means of our mannequin, and in addition current the outcomes of a consumer research that compares our mannequin to ChatGPT and Stanford’s Alpaca. Our outcomes present that Koala can successfully reply to a wide range of consumer queries, producing responses which are usually most popular over Alpaca, and at the very least tied with ChatGPT in over half of the circumstances.
We hope that these outcomes contribute additional to the discourse across the relative efficiency of enormous closed-source fashions to smaller public fashions. Specifically, it means that fashions which are sufficiently small to be run regionally can seize a lot of the efficiency of their bigger cousins if skilled on fastidiously sourced knowledge. This may suggest, for instance, that the neighborhood ought to put extra effort into curating high-quality datasets, as this may do extra to allow safer, extra factual, and extra succesful fashions than merely growing the dimensions of current techniques. We emphasize that Koala is a analysis prototype, and whereas we hope that its launch will present a priceless neighborhood useful resource, it nonetheless has main shortcomings when it comes to content material, security, and reliability, and shouldn’t be used exterior of analysis.
System Overview
Massive language fashions (LLMs) have enabled more and more highly effective digital assistants and chat bots, with techniques akin to ChatGPT, Bard, Bing Chat, and Claude in a position to reply to a breadth of consumer queries, present pattern code, and even write poetry. Most of the most succesful LLMs require large computational assets to coach, and oftentimes use massive and proprietary datasets. This implies that sooner or later, extremely succesful LLMs can be largely managed by a small variety of organizations, and each customers and researchers can pay to work together with these fashions with out direct entry to switch and enhance them on their very own. However, latest months have additionally seen the discharge of more and more succesful freely out there or (partially) open-source fashions, akin to LLaMA. These techniques sometimes fall in need of probably the most succesful closed fashions, however their capabilities have been quickly bettering. This presents the neighborhood with an essential query: will the longer term see more and more extra consolidation round a handful of closed-source fashions, or the expansion of open fashions with smaller architectures that method the efficiency of their bigger however closed-source cousins?
Whereas the open fashions are unlikely to match the dimensions of closed-source fashions, maybe the usage of fastidiously chosen coaching knowledge can allow them to method their efficiency. Actually, efforts akin to Stanford’s Alpaca, which fine-tunes LLaMA on knowledge from OpenAI’s GPT mannequin, recommend that the best knowledge can enhance smaller open supply fashions considerably.
We introduce a brand new mannequin, Koala, which offers a further piece of proof towards this dialogue. Koala is fine-tuned on freely out there interplay knowledge scraped from the online, however with a particular give attention to knowledge that features interplay with extremely succesful closed-source fashions akin to ChatGPT. We fine-tune a LLaMA base mannequin on dialogue knowledge scraped from the online and public datasets, which incorporates high-quality responses to consumer queries from different massive language fashions, in addition to query answering datasets and human suggestions datasets. The ensuing mannequin, Koala-13B, exhibits aggressive efficiency to current fashions as urged by our human analysis on real-world consumer prompts.
Our outcomes recommend that studying from high-quality datasets can mitigate a number of the shortcomings of smaller fashions, possibly even matching the capabilities of enormous closed-source fashions sooner or later. This may suggest, for instance, that the neighborhood ought to put extra effort into curating high-quality datasets, as this may do extra to allow safer, extra factual, and extra succesful fashions than merely growing the dimensions of current techniques.
By encouraging researchers to interact with our system demo, we hope to uncover any sudden options or deficiencies that can assist us consider the fashions sooner or later. We ask researchers to report any alarming actions they observe in our internet demo to assist us comprehend and handle any points. As with all launch, there are dangers, and we are going to element our reasoning for this public launch later on this weblog put up. We emphasize that Koala is a analysis prototype, and whereas we hope that its launch will present a priceless neighborhood useful resource, it nonetheless has main shortcomings when it comes to content material, security, and reliability, and shouldn’t be used exterior of analysis. Beneath we offer an outline of the variations between Koala and notable current fashions.

A major impediment in constructing dialogue fashions is curating coaching knowledge. Distinguished chat fashions, together with ChatGPT, Bard, Bing Chat and Claude use proprietary datasets constructed utilizing important quantities of human annotation. To assemble Koala, we curated our coaching set by gathering dialogue knowledge from the online and public datasets. A part of this knowledge consists of dialogues with massive language fashions (e.g., ChatGPT) which customers have posted on-line.
Fairly than maximizing amount by scraping as a lot internet knowledge as potential, we give attention to gathering a small high-quality dataset. We use public datasets for query answering, human suggestions (responses rated each positively and negatively), and dialogues with current language fashions. We offer the particular particulars of the dataset composition beneath.
ChatGPT Distillation Knowledge
Public Person-Shared Dialogues with ChatGPT (ShareGPT) Round 60K dialogues shared by customers on ShareGPT have been collected utilizing public APIs. To take care of knowledge high quality, we deduplicated on the user-query degree and eliminated any non-English conversations. This leaves roughly 30K examples.
Human ChatGPT Comparability Corpus (HC3) We use each the human and ChatGPT responses from the HC3 english dataset, which comprises round 60K human solutions and 27K ChatGPT solutions for round 24K questions, leading to a complete variety of round 87K question-answer examples.
Open Supply Knowledge
Open Instruction Generalist (OIG). We use a manually-selected subset of elements from the Open Instruction Generalist dataset curated by LAION. Particularly, we use the grade-school-math-instructions, the poetry-to-songs, and the plot-screenplay-books-dialogue datasets. This ends in a complete of round 30k examples.
Stanford Alpaca. We embody the dataset used to coach the Stanford Alpaca mannequin. The dataset comprises round 52K examples, which is generated by OpenAI’s text-davinci-003 following the self-instruct course of. It’s price noting that HC3, OIG, and Alpaca datasets are single-turn query answering whereas ShareGPT dataset is dialogue conversations.
Anthropic HH. The Anthropic HH dataset comprises human scores of harmfulness and helpfulness of mannequin outputs. The dataset comprises ~160K human-rated examples, the place every instance on this dataset consists of a pair of responses from a chatbot, one in every of which is most popular by people. This dataset offers each capabilities and extra security protections for our mannequin.
OpenAI WebGPT. The OpenAI WebGPT dataset features a complete of round 20K comparisons the place every instance contains a query, a pair of mannequin solutions, and metadata. The solutions are rated by people with a choice rating.
OpenAI Summarization. The OpenAI summarization dataset comprises ~93K examples, every instance consists of suggestions from people relating to the summarizations generated by a mannequin. Human evaluators selected the superior abstract from two choices.
When utilizing the open-source datasets, a number of the datasets have two responses, equivalent to responses rated pretty much as good or dangerous (Anthropic HH, WebGPT, OpenAI Summarization). We construct on prior analysis by Keskar et al, Liu et al, and Korbak et al, who show the effectiveness of conditioning language fashions on human choice markers (akin to “a useful reply” and “an unhelpful reply”) for improved efficiency. We situation the mannequin on both a constructive or unfavourable marker relying on the choice label. We use constructive markers for the datasets with out human suggestions. For analysis, we immediate fashions with constructive markers.
The Koala mannequin is carried out with JAX/Flax in EasyLM, our open supply framework that makes it simple to pre-train, fine-tune, serve, and consider varied massive language fashions. We prepare our Koala mannequin on a single Nvidia DGX server with 8 A100 GPUs. It takes 6 hours to finish the coaching for two epochs. On public cloud computing platforms, such a coaching run sometimes prices lower than $100 with preemptible situations.
Preliminary Analysis
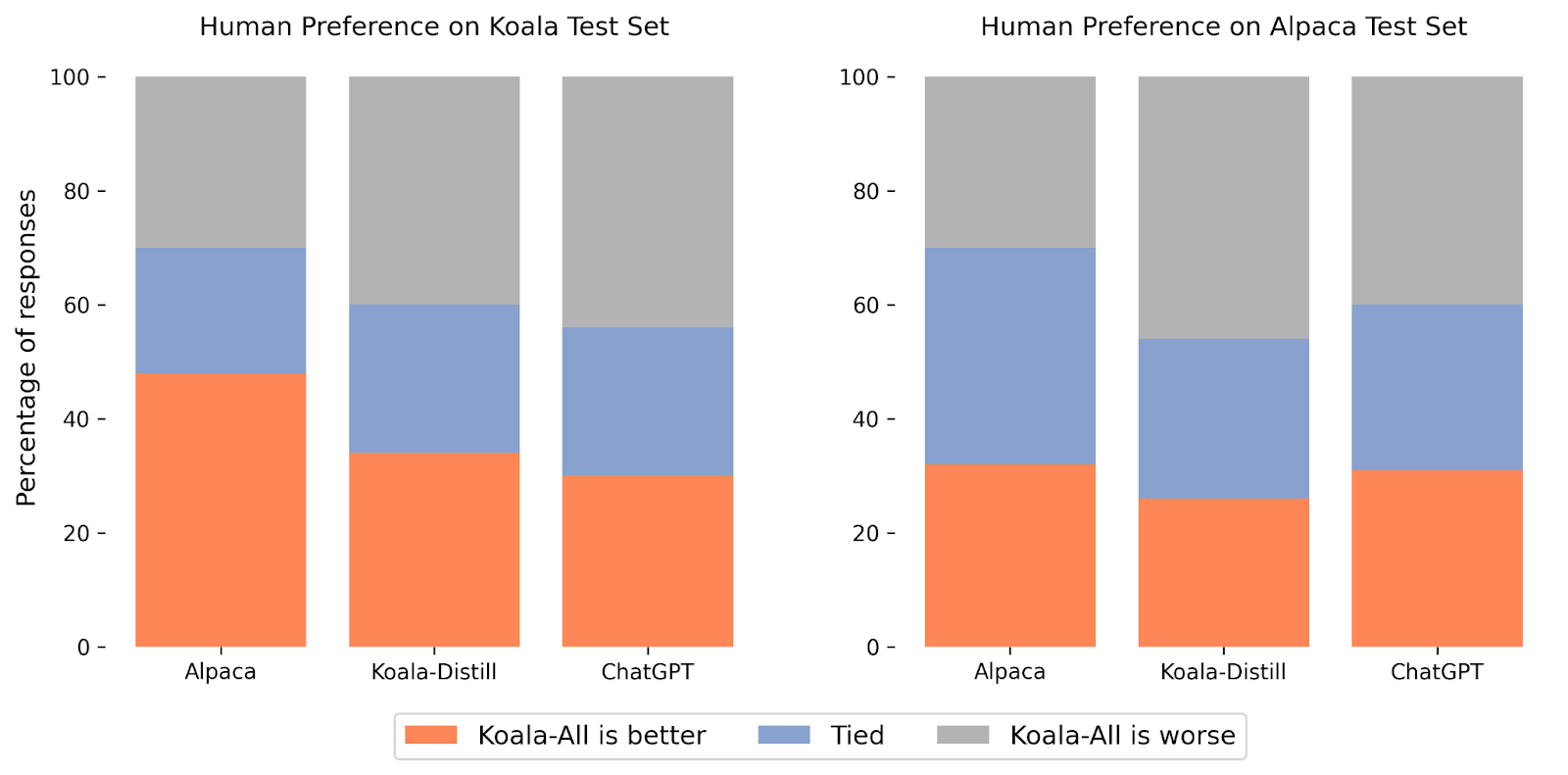
In our experiments, we evaluated two fashions: Koala-Distill, which solely employs distillation knowledge, and Koala-All, which employs all the knowledge, together with each distillation and open-source knowledge. Our goal is to match the efficiency of those fashions and consider the affect of distillation and open-source datasets on last efficiency. We ran a human analysis to match Koala-All with Koala-Distill, Alpaca, and ChatGPT. We current our ends in the determine above. We consider on two completely different units, one consisting of 180 check queries utilized by Stanford’s Alpaca (“Alpaca Check Set”), and our personal check set (“Koala Check Set”).
The Alpaca check set consists of consumer prompts sampled from the self-instruct dataset, and represents in-distribution knowledge for the Alpaca mannequin. To offer a second extra lifelike analysis protocol, we additionally introduce our personal (Koala) check set, which consists of 180 actual consumer queries that have been posted on-line. These consumer queries span varied matters, are typically conversational in fashion, and are doubtless extra consultant of the real-world use circumstances of chat-based techniques. To mitigate potential test-set leakage, we filtered out queries which have a BLEU rating better than 20% with any instance from our coaching set. Moreover, we eliminated non-English and coding-related prompts, since responses to those queries can’t be reliably reviewed by our pool of raters (crowd employees). We launch our check set for tutorial use and future benchmarking.
With these two analysis units, we performed a blind pairwise comparability by asking roughly 100 evaluators on Amazon Mechanical Turk platform to match the standard of mannequin outputs on these held-out units of prompts. Within the scores interface, we current every rater with an enter immediate and the output of two fashions. They’re then requested to evaluate which output is healthier (or that they’re equally good) utilizing standards associated to response high quality and correctness.
On the Alpaca check set, Koala-All exhibited comparable efficiency to Alpaca. Nonetheless, on our proposed check set, which consists of actual consumer queries, Koala-All was rated as higher than Alpaca in practically half the circumstances, and both exceeded or tied Alpaca in 70% of the circumstances. In fact, the extra conversational prompts within the Koala check set extra intently resemble the Koala coaching set, so that is maybe not shocking, however insofar as such prompts extra intently resemble doubtless downstream use circumstances for such fashions, this implies that Koala could be anticipated to carry out higher in assistant-like functions. This implies that knowledge of LLM interactions sourced from examples posted by customers on the net is an efficient technique for endowing such fashions with efficient instruction execution capabilities.
Maybe extra surprisingly, we discovered that coaching on open-source knowledge along with the distillation knowledge (Koala-All) performs barely worse than coaching on simply ChatGPT distillation knowledge (Koala-Distill), as proven by the comparability to Koala-Distill on each datasets. Although the distinction won’t be important, this consequence means that the ChatGPT dialogues are of such prime quality that incorporating even twice as a lot open-source knowledge didn’t result in a big enchancment. Our preliminary speculation was that Koala-All ought to carry out at the very least considerably higher, therefore we used it as our major mannequin in all evaluations, however a possible takeaway from these experiments is that efficient instruction and assistant fashions might be finetuned from LLM backbones akin to LLaMA completely utilizing knowledge from bigger and extra highly effective fashions, as long as the prompts for these responses are consultant of the sorts of prompts that customers will present at test-time. This additionally additional helps the notion that the important thing to constructing sturdy dialogue fashions could lie extra in curating high-quality dialogue knowledge that’s various in consumer queries, quite than merely reformatting current datasets as questions and solutions.
Like different language fashions, Koala has limitations and might be dangerous when misused. We observe that Koala can hallucinate and generate non-factual responses with a extremely assured tone, which is probably going a results of the dialogue fine-tuning. Maybe an unlucky implication of that is that smaller fashions inherit the assured fashion of bigger language fashions earlier than they inherit the identical degree of factuality—if true, it is a limitation that’s essential to review in future work. When misused, the hallucinated responses from Koala can doubtlessly facilitate the unfold of misinformation, spam, and different content material.
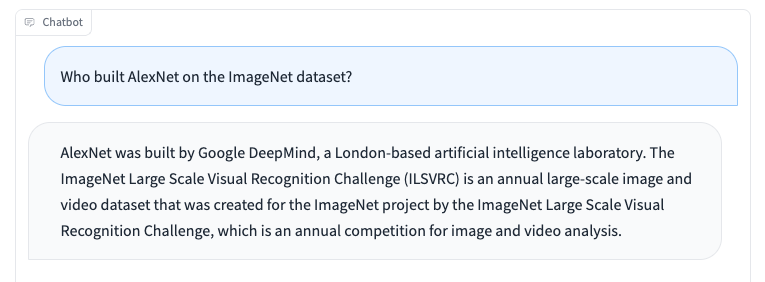
Koalas can hallucinate inaccurate info in a assured and convincing tone. Past hallucinations, Koala shares deficiencies from different chatbot language fashions. A few of which embody:
- Biases and Stereotypes: Our mannequin will inherit biases from the dialogue knowledge it was skilled on, probably perpetuating dangerous stereotypes, discrimination, and different harms.
- Lack of Widespread Sense: Whereas massive language fashions can generate textual content that seems to be coherent and grammatically right, they usually lack frequent sense data that people take with no consideration. This could result in nonsensical or inappropriate responses.
- Restricted Understanding: Massive language fashions can battle to know the context and nuances of a dialogue. They will even have problem figuring out sarcasm or irony, which might result in misunderstandings.
To handle the protection implications of Koala, we included adversarial prompts within the dataset from ShareGPT and Anthropic HH to make the mannequin extra strong and innocent. To additional mitigate potential misuse, we deploy OpenAI’s content material moderation filter in our on-line demo to flag and take away unsafe content material. We can be cautious in regards to the security of Koala, and we’re dedicated to carry out additional security evaluations of it whereas additionally monitoring our interactive demo. General, we determined to launch Koala as a result of we expect its advantages outweigh its dangers.
We’re releasing the next artifacts:
The web demo is a analysis preview supposed for tutorial analysis solely, topic to the mannequin License of LLaMA, Phrases of Use of the info generated by OpenAI, and Privateness Practices of ShareGPT. Another utilization of the web demo, together with however not restricted to industrial utilization, is strictly prohibited. Please contact us In the event you discover any potential violations. Our coaching and inference code is launched below the Apache License 2.0.
We hope that the Koala mannequin will function a helpful platform for future educational analysis on massive language fashions: the mannequin is succesful sufficient to exhibit most of the capabilities that we affiliate with fashionable LLMs, whereas being sufficiently small to be finetuned or utilized with extra restricted compute. Probably promising instructions may embody:
- Security and alignment: Koala permits additional research of language mannequin security and higher alignment with human intentions.
- Mannequin bias: Koala allows us to higher perceive the biases of enormous language fashions, the presence of spurious correlations and high quality points in dialogue datasets, and strategies to mitigate such biases.
- Understanding massive language fashions: as a result of Koala inference might be carried out on comparatively cheap commodity GPUs, it allows us to higher examine and perceive the internals of dialogue language fashions, making (beforehand black-box) language fashions extra interpretable.
The Koala mannequin is a joint effort throughout a number of analysis teams within the Berkeley Synthetic Intelligence Analysis Lab (BAIR) of UC Berkeley.
College students (alphabetical order):
Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace
Advisors (alphabetical order):
Pieter Abbeel, Sergey Levine, Daybreak Music
We categorical our gratitude to Sky Computing Lab at UC Berkeley for offering us with serving backend assist. We wish to thank Charlie Snell, Lianmin Zheng, Zhuohan Li, Hao Zhang, Wei-Lin Chiang, Zhanghao Wu, Aviral Kumar and Marwa Abdulhai for dialogue and suggestions. We wish to thank Tatsunori Hashimoto and Jacob Steinhardt for dialogue round limitations and security. We’d additionally prefer to thank Yuqing Du and Ritwik Gupta for serving to with the BAIR weblog. Please try the weblog put up from Sky Computing Lab a few concurrent effort on their chatbot, Vicuna.
@misc{koala_blogpost_2023,
writer = {Xinyang Geng and Arnav Gudibande and Hao Liu and Eric Wallace and Pieter Abbeel and Sergey Levine and Daybreak Music},
title = {Koala: A Dialogue Mannequin for Tutorial Analysis},
howpublished = {Weblog put up},
month = {April},
12 months = {2023},
url = {https://bair.berkeley.edu/weblog/2023/04/03/koala/},
urldate = {2023-04-03}
}


